

What are Reactive Streams in Java?
13 CommentsLast Updated on October 21, 2024 by jt
If you’re following the Java community, you may be hearing about Reactive Streams in Java. Seems like in all the major tech conferences, you’re seeing presentations on Reactive Programming. Last year the buzz was all about Functional programming, this year the buzz is about Reactive Programming.
In 2016 the buzz was all about Functional programming. In 2017 the buzz is about Reactive Programming.
So, is the attention span of the Java community that short lived?
Have we Java developers forgotten about Functional programming and moved on to Reactive programming?
Not exactly. Actually, the Functional Programming paradigm complements Reactive Programming Paradigm very nicely.
You don’t need to use the Functional Programming paradigm to follow a Reactive Programming. You could use the good old imperative programming paradigm Java developers have traditionally used. Maybe at least. You’d be creating yourself a lot headaches if you did. (Just because you can do something, does not mean you should do that something!)
Functional programming is important to Reactive Programming. But I’m not diving into Functional Programming in this post.
In this post, I want to look at the overall Reactive landscape in Java.
What is the Difference Between Reactive Programming and Reactive Streams?
With these new buzz words, it’s very easy to get confused about their meaning.
Reactive Programming is a programming paradigm. I wouldn’t call reactive programming new. It’s actually been around for awhile.
Just like object oriented programming, functional programming, or procedural programming, reactive programming is just another programming paradigm.
Reactive Streams, on the other hand, is a specification. For Java programmers, Reactive Streams is an API. Reactive Streams gives us a common API for Reactive Programming in Java.
The Reactive Streams API is the product of a collaboration between engineers from Kaazing, Netflix, Pivotal, Red Hat, Twitter, Typesafe and many others.
Reactive Streams is much like JPA or JDBC. Both are API specifications. Both of which you need use implementations of the API specification.
For example, from the JDBC specification, you have the Java DataSource interface. The Oracle JDBC implementation will provide you an implementation of the DataSource interface. Just as Microsoft’s SQL Server JDBC implementation will also provide an implementation of the DataSource interface.
Now your higher level programs can accept the DataSource object and should be able to work with the data source, and not need to worry if it was provided by Oracle or provided by Microsoft.
Just like JPA or JDBC, Reactive Streams gives us an API interface we can code to, without needing to worry about the underlying implementation.
Reactive Programming
There are plenty of opinions around what Reactive programming is. There is plenty of hype around Reactive programming too!
The best starting place to start learning about the Reactive Programming paradigm is to read the Reactive Manifesto. The Reactive Manifesto is a prescription for building modern, cloud scale architectures.
The Reactive Manifesto is a prescription for building modern, cloud scale architectures.
Reactive Manifesto
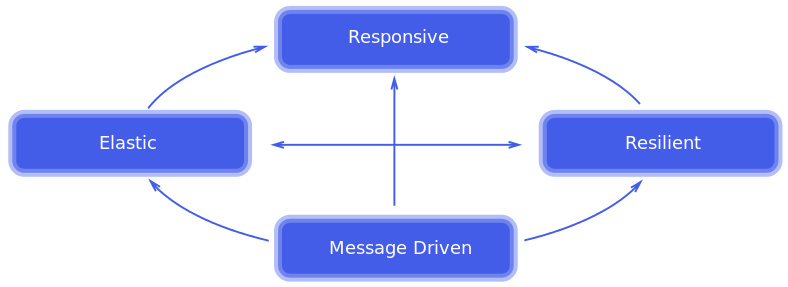
The Reactive Manifesto describes four key attributes of reactive systems:
Responsive
The system responds in a timely manner if at all possible. Responsiveness is the cornerstone of usability and utility, but more than that, responsiveness means that problems may be detected quickly and dealt with effectively. Responsive systems focus on providing rapid and consistent response times, establishing reliable upper bounds so they deliver a consistent quality of service. This consistent behaviour in turn simplifies error handling, builds end user confidence, and encourages further interaction.
Resilient
The system stays responsive in the face of failure. This applies not only to highly-available, mission critical systems — any system that is not resilient will be unresponsive after a failure. Resilience is achieved by replication, containment, isolation and delegation. Failures are contained within each component, isolating components from each other and thereby ensuring that parts of the system can fail and recover without compromising the system as a whole. Recovery of each component is delegated to another (external) component and high-availability is ensured by replication where necessary. The client of a component is not burdened with handling its failures.
Elastic
The system stays responsive under varying workload. Reactive Systems can react to changes in the input rate by increasing or decreasing the resources allocated to service these inputs. This implies designs that have no contention points or central bottlenecks, resulting in the ability to shard or replicate components and distribute inputs among them. Reactive Systems support predictive, as well as Reactive, scaling algorithms by providing relevant live performance measures. They achieve elasticity in a cost-effective way on commodity hardware and software platforms.
Message Driven
Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation and location transparency. This boundary also provides the means to delegate failures as messages. Employing explicit message-passing enables load management, elasticity, and flow control by shaping and monitoring the message queues in the system and applying back-pressure when necessary. Location transparent messaging as a means of communication makes it possible for the management of failure to work with the same constructs and semantics across a cluster or within a single host. Non-blocking communication allows recipients to only consume resources while active, leading to less system overhead.
The first three attributes (Responsive, Resilient, Elastic) are more related to your architecture choices. It’s easy to see why technologies such as microservices, Docker and Kubernetes are important aspects of reactive systems. Running a LAMP stack on a single server clearly does not meet the objectives of the Reactive Manifesto.
 Message Driven and Reactive Programming
Message Driven and Reactive Programming
As Java developers, it’s the last attribute, Message Driven attribute, that interests us most.
Message-driven architectures are certainly nothing revolutionary. If you need a primer on message driven systems, I’d like to suggest reading Enterprise Integration Patterns. A truly iconic computer science book. The concepts in this book laid the foundations for Spring Integration and Apache Camel.
A few aspects of the Reactive Manifesto that does interest us Java developers are, failures at messages, back-pressure, and non-blocking. These are subtle, but important aspects of Reactive Programming in Java.
Failures as Messages
Often in Reactive programming, you will be processing a stream of messages. What is undesirable is to throw an exception and end the processing of the stream of messages.
The preferred approach is to gracefully handle the failure.
Maybe you needed to execute a web service and it was down. Maybe there is a backup service you can use? Or maybe retry in 10ms?
I’m not going to solve every edge case here. The key takeaway is you do not want to loudly fail with a runtime exception. Ideally, you want to note the failure, and have some type of re-try or recovery logic in place.
Often failures are handled with callbacks. Javascript developers are well accustomed to using callbacks.
But callbacks can get ugly to use. Javascript developers refer to this as call back hell.
In Reactive Steams, exceptions are first class citizens. Exceptions are not rudely thrown. Error handling is built right into the Reactive Streams API specification.
Back Pressure
Have you ever heard of the phrase “Drinking from the Firehose”?

Back Pressure is a very important concept in Reactive programming. It gives down stream clients a way to say I’d some more please.
Imagine if you’re making a query of a database, and the result set returns back 10 million rows. Traditionally, the database will vomit out all 10 million rows as fast as the client will accept them.
When the client can’t accept any more, it blocks. And the database anxiously awaits. Blocked. The threads in the chain patiently wait to be unblocked.
In a Reactive world, we want our clients empowered to say give me the first 1,000. Then we can give them 1,000 and continue about our business – until the client comes back and asks for another set of records.
This is a sharp contrast to traditional systems where the client has no say. Throttling is done by blocking threads, not programmatically.
Non-Blocking
The final, and perhaps most important, aspect of reactive architectures important to us Java developers is non-blocking.
Until Reactive came long, being non-blocking didn’t seem like that big of a deal.
As Java developers, we’ve been taught to take advantage of the powerful modern hardware by using threads. More and more cores, meant we could use more and more threads. Thus, if we needed to wait on the database or a web service to return, a different thread could utilize the CPU. This seemed to make sense to us. While our blocked thread waited on some type of I/O, a different thread could use the CPU.
So, blocking is no big deal. Right?
Well, not so much. Each thread in the system will consume resources. Each time a thread is blocked, resources are consumed. While the CPU is very efficient at servicing different threads, there is still a cost involved.
We Java developers can be an arrogant bunch.
They’ve always looked down upon Javascript. Kind of a nasty little language, preferred by script kiddies. Just the fact Javascript shared the word ‘java’ always made us Java programmers feel a bit dirty.
If you’re a Java developer, how many times have you felt annoyed when you have to point out that Java and Javascript are two different languages?
Then Node.js came along.
And Node.js put up crazy benchmarks in throughput.
And then the Java community took notice.
Yep, the script kiddies had grown up and were encroaching on our turf.
It wasn’t that Javascript running in the Google’s V8 Javascript engine was some blazing fast godsend to programming. Java used it have its warts in terms of performance, but its pretty efficient, even compared to modern native languages.
Java used it have its warts in terms of performance, but now its pretty efficient. Even when Java compared to modern native languages.
The secret sauce of Node.js’s performance was non-blocking.
Node.js uses an event loop with limited a number of threads. While blocking in the Java world is often viewed as no big deal, in the Node.js world it would be the kiss of death to performance.
These graphics can help you visualize the difference.
In Node.JS there is a non-blocking event loop. Requests are processed in a non-blocking manner. Threads do not get stuck waiting on other processes.
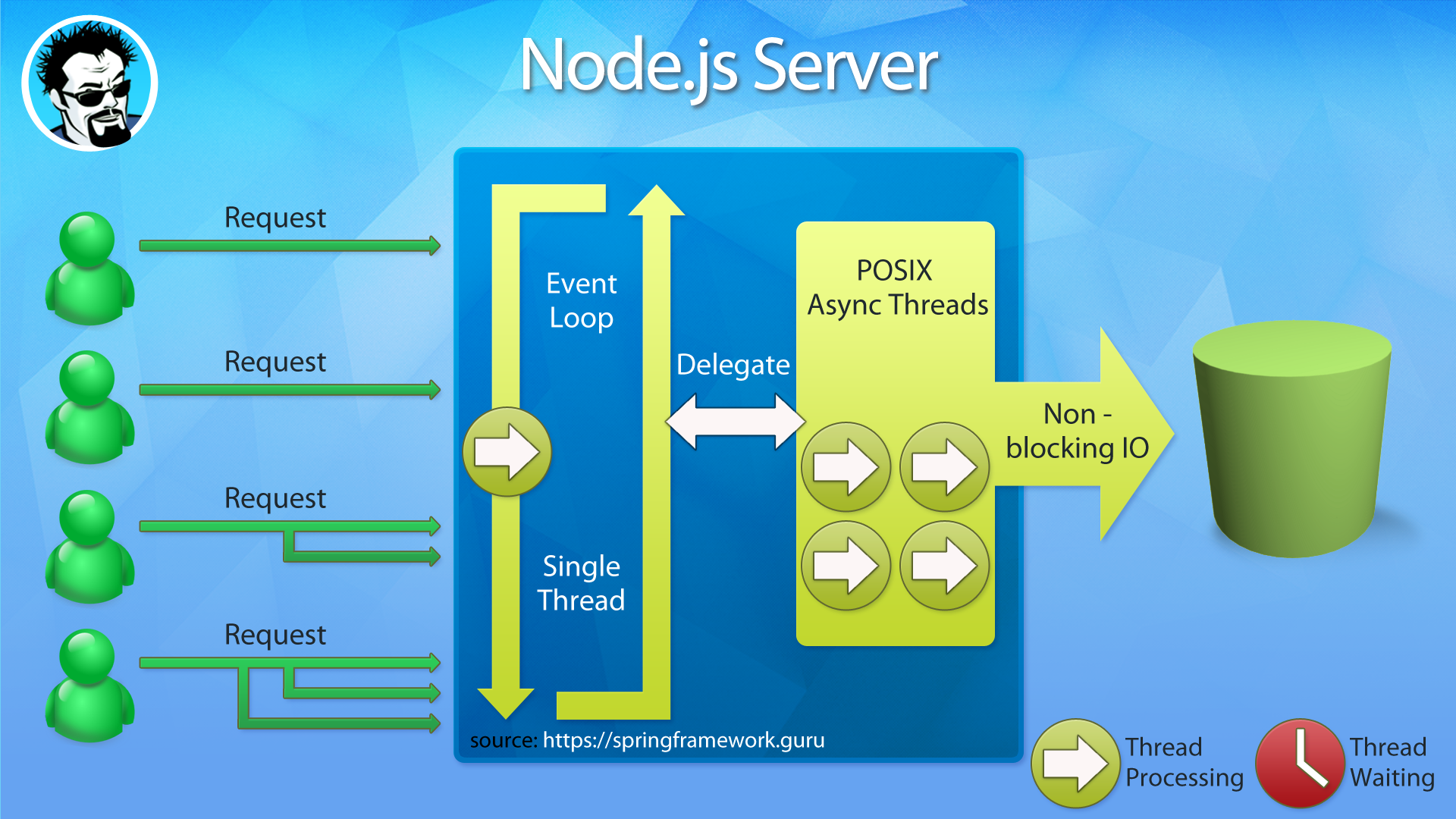
Contrast the Node.JS model to the typical multithreaded server used in Java. Concurrency is achieved through the use of multiple threads. Which is generally accepted due to the growth of multi-core processors.

I personally envision the difference between the two approaches as the difference between a super highway and lots of city streets with lights.
With a single thread event loop, your process is cruising quickly along on a super highway. In a Multi-threaded server, your process is stuck on city streets in stop and go traffic.
Both can move a lot of traffic. But, I’d rather be cruising at highway speeds!

What happens when you move to a non-blocking paradigm, is your code stays on the CPU longer. There is less switching of threads. You’re removing the overhead not only managing many threads, but also the context switching between threads.
You will see more head room in system capacity for your program to utilize.
Non-blocking is a not a performance holy grail. You’re not going to see things run a ton faster.
Yes, there is a cost to managing blocking. But all things considered, it is relatively efficient.
In fact, on a moderately utilized system, I’m not sure how measurable the difference would be.
But what you can expect to see, as your system load increases, you will have additional capacity to service more requests. You will achieve greater concurrency.
How much?
Good question. Use cases are very specific. As with all benchmarks, your mileage will vary.

 The Reactive Streams API
The Reactive Streams API
Let’s take a look at the Reactive Streams API for Java. The Reactive Streams API consists of just 4 interfaces.
Publisher
A publisher is a provider of a potentially unbounded number of sequenced elements, publishing them according to the demand received from its Subscribers.
Publisher
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}Subscriber
Will receive call to Subscriber.onSubscribe(Subscription) once after passing an instance of Subscriber to Publisher.subscribe(Subscriber).
Subscriber
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}Subscription
A Subscription represents a one-to-one lifecycle of a Subscriber subscribing to a Publisher.
Subscription
public interface Subscription {
public void request(long n);
public void cancel();
}Processor
A Processor represents a processing stage—which is both a Subscriber and a Publisher and obeys the contracts of both.
Processor
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}Reactive Streams Implementations for Java
The reactive landscape in Java is evolving and maturing. David Karnok has a great blog post on Advanced Reactive Java, in which he breaks down the various reactive projects into generations. I’ll note the generations of each below – (which may change at any time with a new release).
RxJava
RxJava is the Java implementation out of the ReactiveX project. At the time of writing, the ReactiveX project had implementations for Java, Javascript, .NET (C#), Scala, Clojure, C++, Ruby, Python, PHP, Swift and several others.
ReactiveX provides a reactive twist on the GoF Observer pattern, which is a nice approach. ReactiveX calls their approach ‘Observer Pattern Done Right’.
ReactiveX is a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming.
RxJava predates the Reactive Streams specification. While RxJava 2.0+ does implement the Reactive Streams API specification, you’ll notice a slight difference in terminology.
David Karnok, who is a key committer on RxJava, considers RxJava a 3rd Generation reactive library.
Reactor
Reactor is a Reactive Streams compliant implementation from Pivotal. As of Reactor 3.0, Java 8 or above is a requirement.
The reactive functionality found in Spring Framework 5 is built upon Reactor 3.0.
Reactor is a 4th generation reactive library. (David Karnok is also a committer on project Reactor)
Akka Streams
Akka Streams also fully implements the Reactive Streams specification. Akka uses Actors to deal with streaming data. While Akka Streams is compliant with the Reactive Streams API specification, the Akka Streams API is completely decoupled from the Reactive Streams interfaces.
Akka Streams is considered a 3rd generation reactive library.
Ratpack
Ratpack is a set of Java libraries for building modern high-performance HTTP applications. Ratpack uses Java 8, Netty, and reactive principles. Ratpack provides a basic implementation of the Reactive Stream API, but is not designed to be a fully-featured reactive toolkit.
Vert.x
Vert.x is an Eclipse Foundation project, which is a polyglot event driven application framework for the JVM. Reactive support in Vert.x is similar to Ratpack. Vert.x allows you to use RxJava or their native implementation of the Reactive Streams API.
Reactive Streams and JVM Releases
Reactive Streams for Java 1.8
With Java 1.8, you will find robust support for the Reactive Streams specification.
In Java 1.8 Reactive streams is not part of the Java API. However, it is available as a separate jar.
Reactive Streams Maven Dependency
<dependency> <groupId>org.reactivestreams</groupId> <artifactId>reactive-streams</artifactId> <version>1.0.0</version> </dependency>
While you can include this dependency directly, whatever implementation of Reactive Streams you are using, should include it automatically as a dependency.
Reactive Streams for Java 1.9
Things change a little bit when you move to Java 1.9. Reactive Streams become part of the official Java 9 API.
You’ll notice that the Reactive Streams interfaces move under the Flow class in Java 9. But other than that, the API is the same as Reactive Streams 1.0 in Java 1.8.
Conclusion
At the time of writing, Java 9 is right around the corner. In Java 9, Reactive Streams is officially part of the Java API.
In researching this article, it’s clear the various reactive libraries have been evolving and maturing (ie David Karnok generations classification).
Before Reactive Streams, the various reactive libraries had no way of interoperability. They could not talk to each other. Early versions of RxJava were not compatible with early versions of project Reactor.
But on the eve of the release of Java 9, the major reactive libraries have adopted the Reactive Streams specification. The different libraries are now interoperable.
Having the interoperability is an important domino to fall. For example, Mongo DB has implemented a Reactive Streams driver. Now, in our applications, we can use Reactor or RxJava to consume data from a Mongo DB.
We’re still early in the adaptation of Reactive Streams. But over the next year or so, we can expect more and more open source projects to offer Reactive Streams compatibilities.
I expect we are going to see a lot more of Reactive Streams in the near future.
It’s fun time to be a Java developer!







































Peter Sotos
Great article John! Though lots of duplicates; you might want to clean that up.
jt
Thanks – I’ll take a look.
I’m using Gramerly – which is cool, but wigs out on the WP editor, causing weird stuff.
Jim
Hi – could you clarify something for me regarding the “backpressure” section?
“In a Reactive world, we want our clients empowered to say give me the first 1,000. Then we can give them 1,000 and continue about our business – until the client comes back and asks for another set of records.
This is a sharp contrast to traditional systems where the client has no say. Throttling is done by blocking threads, not programmatically.”
I guess I’m struggling to understand how simple pagination (limit/offset) does not also solve this problem, in the classic “non-reactive” world.
jt
It’s very similar, but this is at a much more granular level. Rather than a traditional CRUD style application, think in terms of streams of data. Like processing data from a GPS running watch. Or monitoring the trades of a stock ticker.
Arnold
Very useful summary and reference. Bookmarked!
maciejpe
Nice one, thanks!
Rajeev Jayaram
But as long as JDBC is using Blocking api, do we have any great advantage in using Rx in relational database application. Nice article…learnt quite a bit of fundamental stuff in Rx
jt
I’m not sure. In theory you should still see some benefit. But I’d be curious to see benchmarks.
Pavlo M
This is the great question 🙂 I think the first question here hardware. If you have HDD which actually reads just one track at the moment (Most of HDDs!) you will not get anything significant. The other thing if you have device which allows parallel read/write. In this case you can open few connections (use connections pool) and each of your application threads will read from it’s own connection – then yes you will see the difference. Of cause you can create threads in classic way or with reactive approach, and I think you will not note the performance difference.
Venkat
It’s great nutshell description, Thanks!
I have query here…
As you(reactive streaming) mentioned publisher publish data on Subscriber demand, that means If no request from subscriber publisher wait for input, right? If that is the case I consider it as producer blocked?
Pavlo M
Thanks for article. I found a lot of stuff you wrote great. Though it could be useful to say about concurrency first or at least at very top of article.
I think many people misunderstand what reactive and non-blocking API is. In fact node.js uses parallel processing but developers not need to know this as it done at lower level (not in JavaScript but rather c++ core). Non blocking means just one non-blocking process(event loop) starts lower level tasks (and tasks are can run in parallel but you cannot manage this with JavaScript).
About Java. I not get any info from Java 9 reactive standard libs yet, But with RxJava we have few schedulers to explicitly manage threads pool. It looks like just wrong to say anything about classic Java threads effectiveness in comparison with reactive approach, because under the hood they are seems use same classic threads. Java allows you to manage them on lower level, while with NodeJS it is not allowed and concurrency in NodeJS available only with reactive approach.
Saying that your node.js diagram and multi threaded server picture seems misleading
With reactive approach I just see one good thing we can get – return from task in separate thread as soon as it done, while with traditional threads we need some shared resource reference in thread executed task to report (and it needs to be synchronized). I am still not sure but possible reactive style would be more clear to implement and maintain. That is all developers can get with it. Please correct if I wrong. Reactive approach is very new for me.
sean
What about debugging? Is it easy to debug? Under the hood they juggle with threads + functional programming (I smell callback hell). Even one of this of its own gives me nightmares thinking about debugging, two of this expecting me big traumatas to work/debug with, or is this all abstracted far far away from the API-user?